
Python爬虫为什么叫爬虫 Python爬虫技术是什么
说到Python爬虫,很多小伙伴会好奇为啥叫“爬虫”呢?其实啊,爬虫就是指在互联网大网里面爬行的那只“蜘蛛”。想象一下,互联网就像一张巨大的网,爬虫就像那只在网上不断爬来爬去的小蜘蛛,遇到自己感兴趣的猎物——也就是我们需要的数据资源,它们就会把这些“猎物”通通抓取下来。比如说,当爬虫访问一个网页时,网页中有很多通往其他网页的链接,也就是所谓的超链接,这时候爬虫就能顺着这些“路”继续往下爬,获取更多的信息。
那到底爬虫技术是啥意思呢?简而言之,爬虫技术就是一种能够自动化浏览和采集网络信息的程序技术,又叫网络爬虫或者网络蜘蛛。它能自动访问网页,采集网页里的各种内容,让人省了大量手动查找数据的时间。爬虫技术应用特别广泛,比如搜索引擎就是靠它来抓取和更新海量网页内容的。它自动跑遍网络,采集得到的信息再存到数据库里,让我们可以高效搜索和使用。
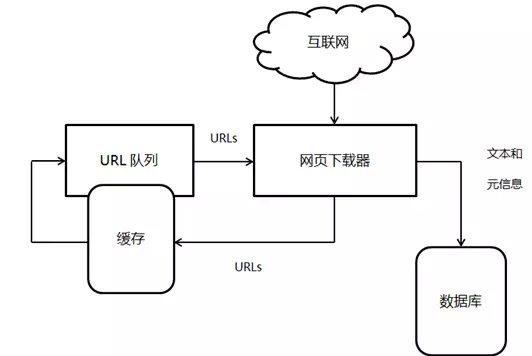
Python爬虫的原理和实现核心 Python爬虫怎么弄
说白了,Python爬虫也是靠技术模拟浏览器向网站发请求,拿到网页资源后分析并提取自己需要的数据。这个过程其实挺简单的,主要分几个步骤:
- 发送请求:用程序像浏览器一样发起HTTP请求,得到网页返回的HTML代码、JSON数据甚至图片视频等二进制资源。
- 解析数据:拿到数据后利用解析库去提取关键信息,比如用BeautifulSoup或者lxml来解析HTML代码。
- 数据存储:把提取到的数据保存到数据库或文件里,方便后续处理和分析。
具体怎么用Python写爬虫呢?你可以选用不同工具:
- Requests:这是个超简单的HTTP请求库,拿静态页面的源码简直妥妥的。
- BeautifulSoup:它能帮你快速解析HTML,找数据便利到爆。
- Selenium:当遇到动态渲染页面时,用它模仿真实浏览器操作完全没压力。
- Scrapy:如果你是专业目标,Scrapy框架一站式搞定调度、并发还有去重,各种复杂需求轻松处理。
要是你想简单演练个小爬虫,这边给你个示范,重点用Requests拿页面,再用BeautifulSoup解析:
import requests
from bs4 import BeautifulSoup
url = 'https://example.com'
response = requests.get(url)
soup = BeautifulSoup(response.text, 'html.parser')
print(soup.title.text)
哎呀这流程其实很直观,只要会点Python,学会这些工具,写个简单的小爬虫妥妥的,超级有成就感!
相关问题解答
-
Python爬虫到底是做什么用的?
嘿,这问题问得好!Python爬虫就是帮你自动去网络上“采集”信息的小帮手。比如说你想收集新闻、商品价格、数据资料,爬虫程序就能自动访问网站,搜集你想要的内容,让你不费吹灰之力就有一大堆宝贵数据,超级省事! -
我不会写代码,能不能学会Python爬虫?
完全没问题!只要你愿意尝试,网上教程、视频多得数不过来,Python语法也超级简单,代码写起来像写英语句子一样自然。慢慢摸索,动手实践,没多久你就能轻松写出自己的第一个爬虫啦,放心大胆试吧! -
动态网页爬取和普通网页有什么区别?
这个说起来也不难懂。普通网页就是服务器直接给你发HTML代码,爬虫一抓就到;动态网页就有点调皮,内容是通过JavaScript加载的,普通请求拿不到你想要的数据,需要用Selenium这种模拟浏览器行为的工具,或者抓包分析数据接口,才能拿出真正想要的信息。 -
爬虫是不是很容易违反法律?
这个嘛,没错,爬虫用得不对可是会踩雷的!但只要你遵守网站的robots.txt规则,不去恶意破坏和盗用数据,基本上问题不大。使用爬虫前,先了解清楚目标网站的使用政策,多一点尊重和谨慎,就能玩得开心又安全啦!








新增评论